
Python爬虫基础之(二)Robots协议
在上一篇中,我们讲过网络爬虫是游走在法律边缘地带的“灰色”技术,所以这一篇就需要来好好讲讲网络爬虫规范了。
Robots协议(Robots Exclusion Standard)网络爬虫排除标准
1994年6月30日,在经过搜索引擎人员以及被搜索引擎抓取的网站站长共同讨论后,正式发布了一份行业规范,即robots.txt协议。在此之前,相关人员一直在起草这份文档,并在世界互联网技术邮件组发布后,这一协议被几乎所有的搜索引擎采用,包括最早的altavista,infoseek,后来的google,bing,以及中国的百度,搜搜,搜狗等公司也相继采用并严格遵循。
Robots协议存在于网站根目录下的robots.txt文件中,用于告知网络爬虫哪些页面可以抓取,哪些不可以。
下面来看一个Robots协议的真实案例:
展天联盟网站Robots协议
浏览器搜索:https://m.toutiao.com/robots.txt
User-Agent: *
Disallow: /
Allow: /$
#注意英文冒号后紧跟一个空格
正如网页所显示,robots.txt主要由User-Agent,Disallow,Allow三项内容组成。
User-agent: 表明搜索引擎爬虫名字
Disallow: 表示禁止抓取的页面
Allow: 表示允许抓取的页面
*: 表示匹配0或任意长度的任意字符
$: 表示匹配行结束
/: 表示该目录下的所有目录文件和页面
其他的一些Robots协议(并不是所有网站都有Robots协议):
http://www.baidu.com/robots.txt
http://news.sina.com.cn/robots.txt
http://www.moe.edu.cn/robots.txt(无Robots协议)
由上可知,只需在网站主页url后面输入/robots.txt便可查看Robots协议了。
修改User-Agent来访问网页
Robots协议中会针对不同的浏览器来限制抓取资源,例如:User-Agent: Baiduspider,就是指定百度搜索引擎。当我们所使用的搜索引擎被限制访问时,可以修改User-Agent来“骗”过Robots协议,也就是使用网站允许的User-Agent。
我们可以使用任意带有抓包工具的浏览器,这里使用chrome浏览器作说明:
打开展天联盟网页,右键打开检查。
选择Network选项,同时刷新网页。
随便点击Name下的一个文件。
查看Headers内容,下滑找到User-Agent。
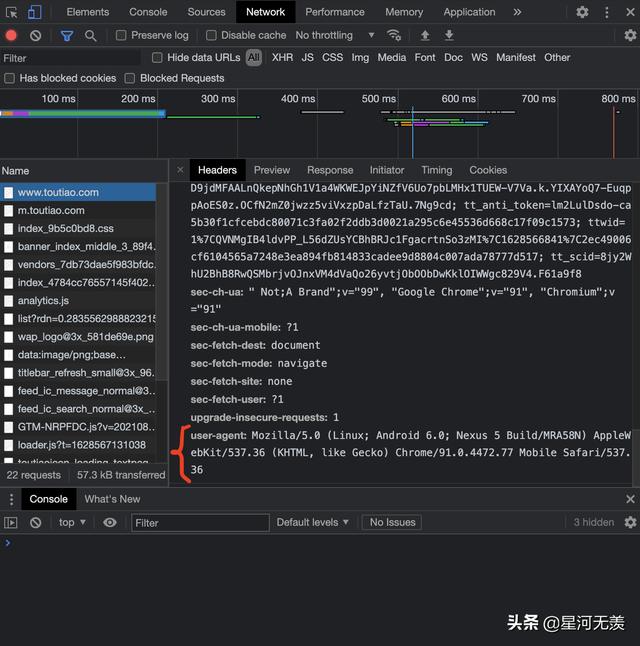
这就是我们要找的User-Agent了,下面给出代码:
import requests
# 设置url为展天联盟网站网址
url = "https://www.toutiao.com/"
# 调用get方法发送请求
r = requests.get(url)
# 打印请求状态码
print(r.status_code)
# 打印headers信息,可以看出User-Agent是'python-requests/2.25.1'
print(r.request.headers)
# 构造字典改变headers内容
ua = {'User-Agent':'Mozilla/5.0'}
r = requests.get(url, headers = ua)
# 打印新的headers信息,可以看到修改完成
print(r.request.headers)
以上方法主要应用于服务器在进行来源审查时禁止了我们的request请求,我们基于网站允许的User-Agent修改请求以达到成功访问的目的。
Robots协议的使用
Robots协议是建议而非约束性,网络爬虫可以不遵守,但是需要承担相应的法律风险。
在爬取网页资源前,要自动或者是人工识别Robots协议,再进行内容的爬取。
值得注意的是:如果当爬虫进行类人访问时,可以不遵守Robots协议。也就是说,当爬虫爬取的内容非常少,访问次数极不频繁,相当于一个人在访问网站,可以看作是一个人在访问浏览器,此时不太会造成爬虫带来的性能、法律和隐私问题,Robots协议便是白纸一张。
小结
本篇内容介绍了网络爬虫的行业规范——Robots协议,及其相关内容。
本文来自苏默晨投稿,不代表胡巴网立场,如若转载,请注明出处:https://www.hu85.com/278214.html
相关推荐
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 xxxxx@qq.com 举报,一经查实,本站将立刻删除。